Não sei se tem alguma coisa a ver, pois meu “SMART Status” não oferece tantos detalhes.
Algo assim começou a “aparecer” aqui, com 1 dos meus discos, mas só em algumas das distros que já chegaram ao KDE 5.22.0.
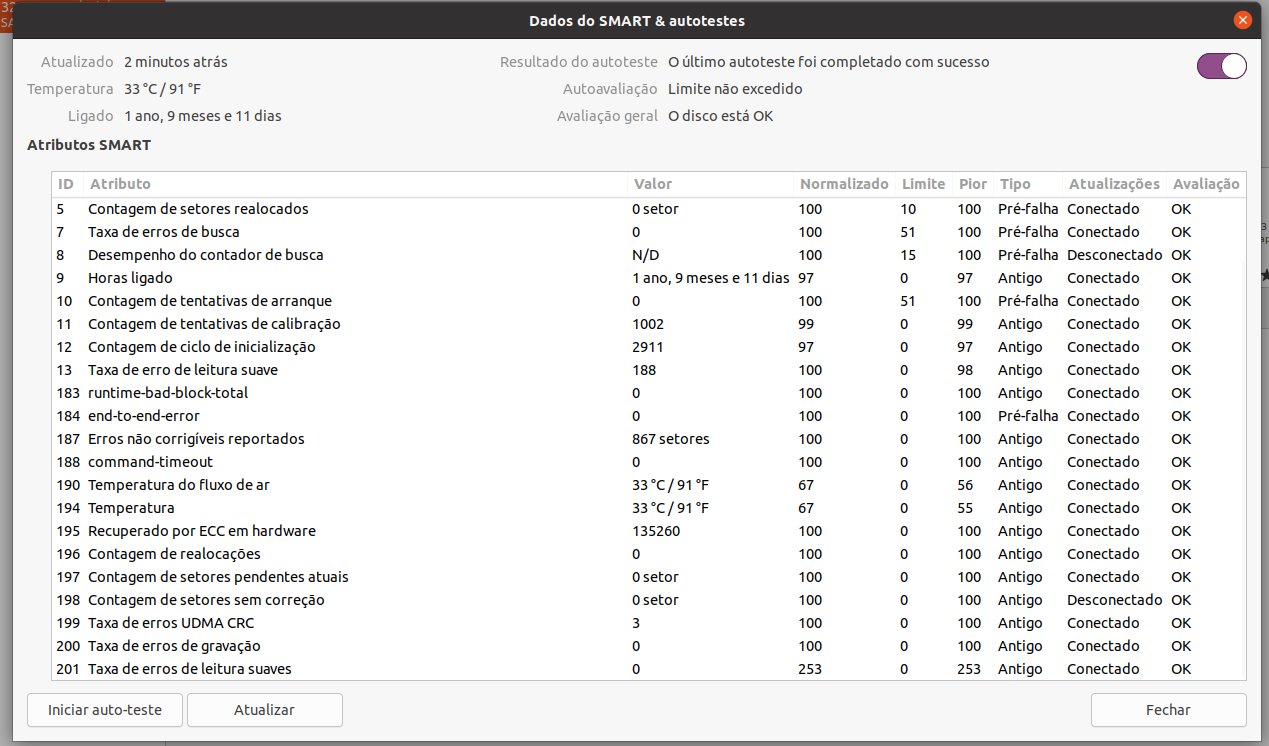
Clicando no aviso, o SMART Status diz que pode não ser nada, mas que precisaria fazer uma análise mais pipipi popopó. Faça backup, acione a Embaixada, chame o advogado, contate o fabricante etc.
Como se vê (acima), a única ação oferecida é “Ignorar” ─ por isso, não fui adiante.
Acontece no openSUSE Tumbleweed (desde KDE 5.22.0 até 5.22.2), KDE Neon (desde KDE 5.22.0 até 5.22.2) e PCLinuxOS (desde KDE 5.22.0 até 5.22.2).
Mas não acontece no Void (até KDE 5.22.1), nem no Arch (até KDE 5.22.2).
No momento, estou no Debian, onde gozo da feliz inocência do KDE 5.20.5. ─ Nenhuma mensagem aterrorizante. ─ Esta boa e velha versão oferece ações de “Ignorar”, fazer Backup, ou abrir o “KDE Partition Manager”.
Em Device >> SMART Status, nuvens brancas em céu azul, no alto; e embaixo uma sucessão de “Good” e “Not Available” (afinal é um HDD de mais de 10 anos, nem sei se a Samsung ainda existe).
Salvei o Relatório, abri no Chromium, e continua bonito na parte superior ─ Good, Success, Healthy, zero bad setor. ─ Na parte de baixo, uma sucessão de “Old-Age” e “Pre-Failure”.
Brrrrrrr… Medo!!!
Bom, por enquanto, não posso abrir mão desse HDD, fabricado em 2008:
Local Storage: total: 2.84 TiB used: 838.23 GiB (28.8%)
Sata #1 ID-1: /dev/sda SSD Sata3 Kingston SA400S37480G 447.13 GiB 480 GB
Sata #3 ID-2: /dev/sdb HDD Sata3 Seagate ST1000DM003-1SB102 931.51 GiB 1 TB (2016)
Sata #4 ID-3: /dev/sdc HDD Sata2 Maxtor STM3320613AS 298.09 GiB 320 GB (2008)
Sata #5 ID-4: /dev/sdd HDD Sata2 Samsung HD322HJ 298.09 GiB 320 GB (2008)
USB ext ID-5: /dev/sde SSD USB2 Samsung S2 Portable 931.51 GiB 1 TB (2011)
Por enquanto, continuo fazendo backups semanais, em geral aos Domingos ─ no HDD Seagate 1TB de 2016 ─ e guardando o backup anterior no SSD externo USB2 de 1TB, fabricado em 2011.
Em tempo: - O GParted, que prefiro, não oferece SMART Status.