Boa tarde, camaradas.
Preciso de uma mão para automatizar a exclusão de termos que ligeiramente parecidos via regex, parecem com isso sempre mantendo o início igual:
Version:0.9 StartHTML:0000000105 EndHTML:0000001631 StartFragment:0000000141 EndFragment:0000001591
Version:0.9 StartHTML:0000000105 EndHTML:0000000631 StartFragment:0000000141 EndFragment:0000000591
Poderia citar um exemplo mais claro dos dados que você está analisando e das linhas que você quer excluir?
Chuto que você busca algo como ^.*:[0-9]+$ (linha com qualquer sequência de caracteres, seguida de dois pontos, seguida de um ou mais dígitos).
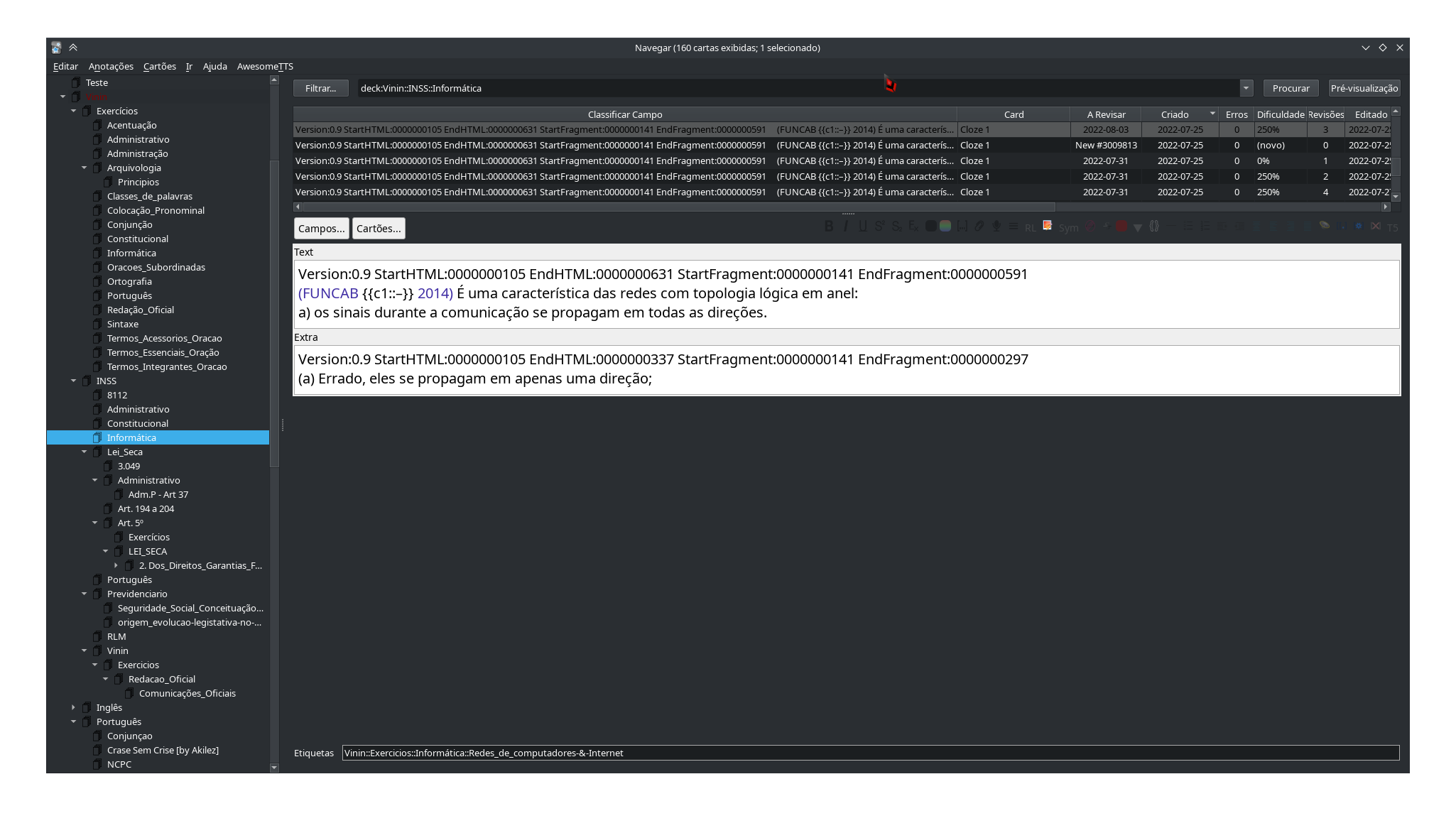
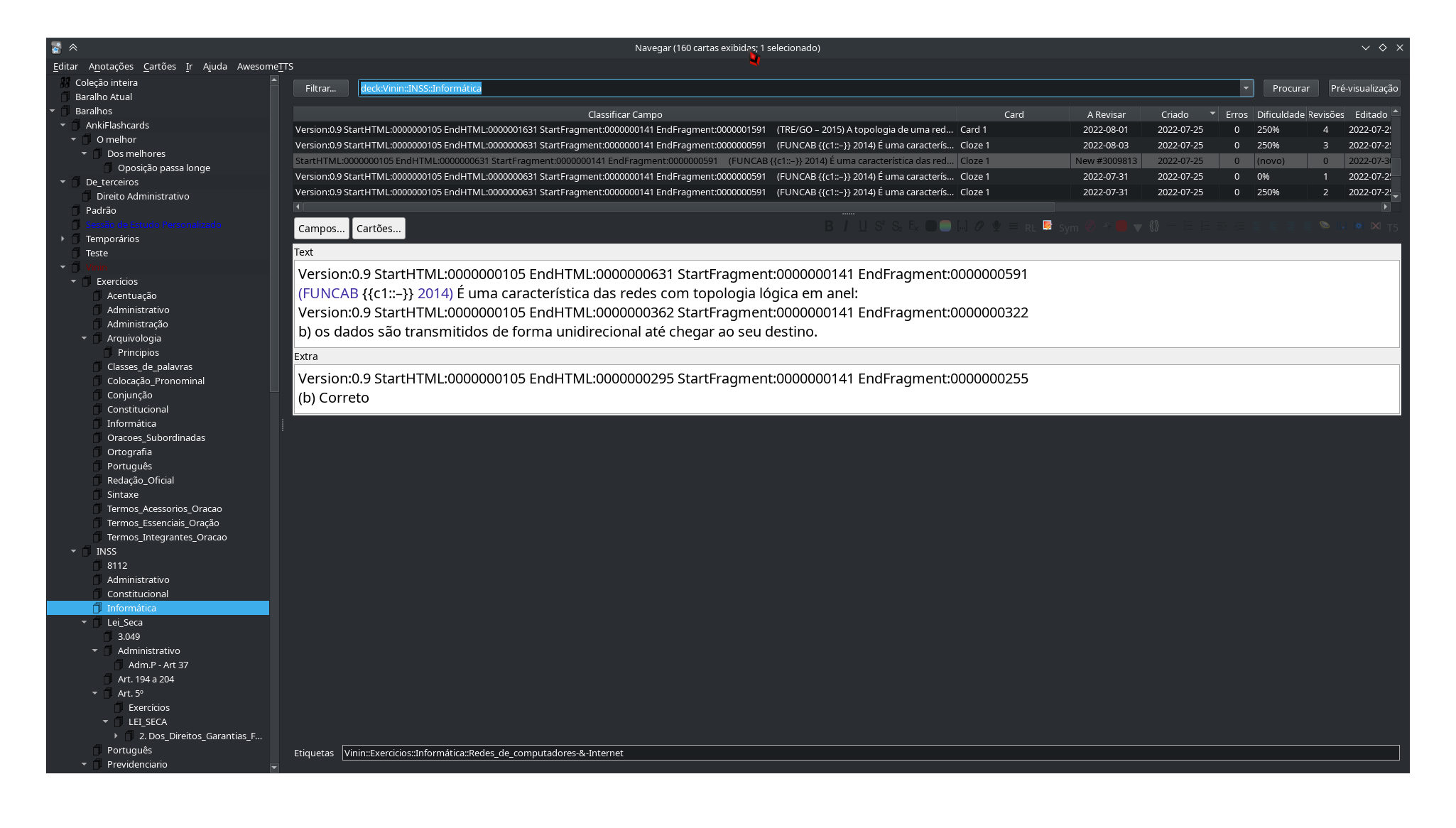
Eu quero apagar a linha que sempre tem esta parte fixa Version:0.9 StartHTML:0000000105
Pode usar o grep -Fv 'Version:0.9 StartHTML:0000000105', nem precisa estritamente de regex.
Ou, se houver linhas com esse padrão no meio, grep -Fv '^Version:0\.9 StartHTML:0000000105' (note o ^, que assegura um início de linha, e \. para impedir o significado especial do ponto).
Infelizmente não está dando certo, mas mesmo assim obrigado.
Quem manja de como fazer isso no Anki. Agradeço.
Talvez você esteja procurando por:
grep -vP 'Version:\d.\d* StartHTML:\d*'
Ou você que realmente apenas remover os contendo StartHTML:0000000105?
grep -v 'StartHTML:0000000105'
Mas se você quer realmente remover as linhas que contem exatamente “Version:0.9 StartHTML:0000000105”, é como o @Capezotte apontou. Você está fazendo assim?:
cat arquivo.txt | grep -Fv 'Version:0.9 StartHTML:0000000105'
Anki
Infelizmente não conheço essa ferramenta, mas se ela suporta regex, talvez você esteja buscando uma dessa regex:
^(?!Version:0.9 StartHTML:0000000105).*
Quero apagar a linha que tem sempre isso Version:0.9 StartHTML:0000000105
Se você puder dar um pouco mais de contexto sobre o que é esse Anki, ele suporta regex? Se sim, como ele usa regex, via match linha por linha?
Sim, Romulo. Não conheço regex, mas isso apagou parte do conteúdo.
^(?!Version:0.9 StartHTML:0000000105).*
removeu as linhas que você desejava remover?
Somente uma a parte do Version:0.9 StartHTML:0000000105
Como assim, removeu parte da linha? se puder dar um exemplo do resultado.
Ficou assim uma delas:
StartHTML:0000000105 EndHTML:0000000631 StartFragment:0000000141 EndFragment:0000000591
se você puder mandar um print do local onde você aplica a regex, pois é preciso saber como ele usa a regex.
Por exemplo, essa regex que eu te mandei é para dar match se o texto não iniciar com Version:0.9 StartHTML:0000000105 seguido de qualquer caractere repetido 0 ou mais vezes.
Mas dependendo de como esse tal Anki faz uso do regex, essa regra não vai devolver o que você busca.
@Vinicus infelizmente ainda não está claro como esse programa funciona, você tem o site desse tal Anki?
Não está bem claro se você aplica na linha, ou em várias, nem como é aplicado esse regex. Talvez seja melhor esperar alguém que conhece esse programa.
Só tem que ver se é isso que você quer, isso vai substituir padrões em um texto por algo, e não filtrar textos. Você precisa ser mais claro sobre o que você realmente quer fazer. Substituir coisas nos textos? somente mostrar textos que não tem o padrão (Busca)? Será que você não quer:
https://docs.ankiweb.net/searching.html#regular-expressions
caso você queira apenas remover Version:0.9 StartHTML:0000000105 das linhas, o regex é outro. é um regex de substituição dai.
Se você quer apagar todo o texto:
Version:0.9 StartHTML:0000000105.*
Mas replace with tem de ficar vazio.